I turned a legacy dictionary software into a Telegram bot: hVortaroBot
I had fun reverse engineering the dictionary data and adding some word guessing games!
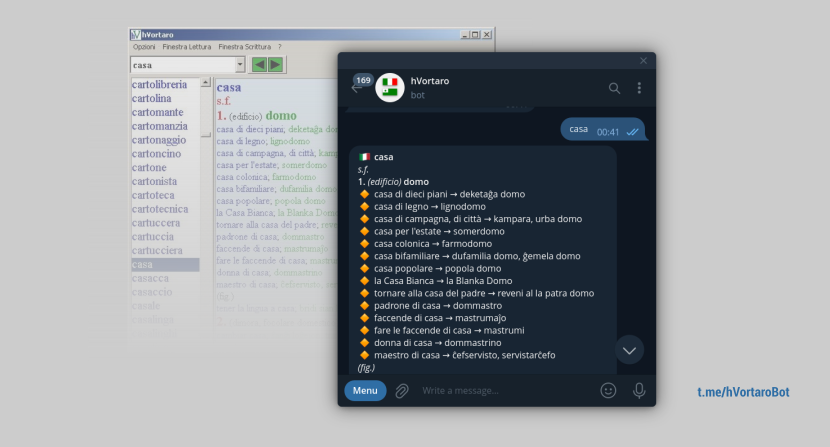
hVortaro
The dictionary is called hVortaro, it is an Italian-Esperanto dictionary and is available in both a web version and a desktop version.
To build the Telegram bot, I decided to use the dictionary data which comes with the desktop version, so I downloaded it from this page, where the publisher, quite conveniently, also provides links to download only the data files without the application.
The zip file I download contained two files with not well known extensions, so I used the file command to try to determine the file types:
$ file itaesps.*
itaesps.bin: data
itaesps.idx: dataUnfortunately it didn't help much, so further investigation was required.
I noticed that the file itaesps.idx (1.8 Mb) was much smaller than itaesps.bin (9.2 Mb). Both its size and extension suggested that it may be an index, and this can be confirmed looking for readable text in it:
$ strings itaesps.idx | less
La divinis|
a fortiori|
a gogo|
a jour|
Aa la belle etoile|
oa la coque|
a la page|
Wa latere|
…This appears to be a list of terms: a divinis, a fortiori, a gogo, a la belle etoile, a la coque, a la pace, a latere…
On the other hand, itaesps.bin contains the definitions, starting with the one for the term a:
$ strings itaesps.bin | less
a (1)#
s.f.
a come Adamo
a kiel Adamo#
dall'a alla zeta
de a
is zo#
a (2)#
prep.#
(compl. di termine)
parla a tuo padre
parolu al via patro#
…Decoding the index permalink
Going back to itaesps.idx and inspecting its content:
$ hexdump -C itaesps.idx | less
00000000 23 00 00 00 01 61 7c a3 00 00 1b 4c 61 20 64 69 |#....a|....La di|
00000010 76 69 6e 69 73 7c a3 00 00 1b ba 61 20 66 6f 72 |vinis|.....a for|
00000020 74 69 6f 72 69 7c a3 00 00 1b eb 61 20 67 6f 67 |tiori|.....a gog|
00000030 6f 7c a3 00 00 1c 1c 61 20 6a 6f 75 72 7c a3 00 |o|.....a jour|..|
…
001b3030 a3 00 92 b1 1d 7a 75 72 69 67 6f 7c 5e 00 92 b1 |.....zurigo|^...|
001b3040 40 7a 75 72 69 6b 6f 7c a3 00 92 b1 63 7a 75 7a |@zuriko|....czuz|
001b3050 7a 65 72 65 6c 6c 6f 6e 65 7c |zerellone||One can notice that it starts with the term a and follows this pattern:
- Each term is followed by a pipe
|(0x7c). - Each term is preceded by 5 bytes.
Looking at the 5 byte block, it seems that its last 4 bytes contain an increasing value:
00 00 00 01— a00 00 1b 4c— a divinis00 00 1b ba— a fortiori- …
00 92 b1 40— zuriko00 92 b1 63— zuzzerellone
Using this value as a byte offset for itaesps.bin the corresponding definitions are found. For example, for a fortiori (0x1bba):
$ hexdump -C itaesps.bin -s 0x1bba | less
00001bba 00 2d 00 a4 61 20 66 6f 72 74 69 6f 72 69 23 ac |.-..a fortiori#.|
00001bca 28 6c 61 74 2e 29 23 a7 6c 2e 61 76 2e b4 64 65 |(lat.)#.l.av..de|
00001bda 73 20 70 6c 69 2c b4 74 69 6f 6d 20 70 6c 69 23 |s pli,.tiom pli#|
00001bea 08 00 2d 00 a4 e0 20 67 6f 67 6f 23 ac 28 66 72 |..-... gogo#.(fr|
00001bfa 2e 29 23 a7 6c 2e 61 76 2e b4 70 6c 65 6e 61 62 |.)#.l.av..plenab|
00001c0a 75 6e 64 65 2c b4 70 6c 65 6a 61 62 75 6e 64 65 |unde,.plejabunde|
…I used this information in my app to load the index in ram as a hash table (a python dictionary). Of course one could skip this file altogether and directly use the content of itaesps.bin to populate a database of some sort, but I preferred to use those files themselves as data source. This approach allows me to update the data just by replacing these two files with their eventual new version in the case of a dictionary upgrade.
Decoding the content permalink
First of all, I tried to detect the charset getting a chunk of text free from markup or control characters for inspection:
$ hexdump -C itaesps.bin | less
…
000dd680 e8 20 75 6e 61 20 62 65 6c 6c e9 7a 7a 61 a5 73 |. una bell.zza.s|
000dd690 75 72 20 6c 61 20 61 8b 74 6f 89 6f 73 65 6f 20 |ur la a.to.oseo |
000dd6a0 6f 6e 69 20 6b 75 72 61 73 20 70 6c 65 6e 83 75 |oni kuras plen.u|
000dd6b0 65 23 a9 61 20 63 61 73 61 20 74 75 61 20 73 69 |e#.a casa tua si|
…Comparing this with the web version of the definition, I know that the text starting at 0xdd68f and ending at 0xdd6b1 should be decoded as "sur la aŭtoŝoseo oni kuras plenĝue". This text is a good specimen because it contains several non ASCII characters (ŭ, ŝ, ĝ). I put this text in a new file and used the file command to detect its charset:
$ dd if=itaesps.bin bs=1 skip=$((0xdd68f)) count=$((0xdd6b1 - 0xdd68f)) of=test.txt
34+0 records in
34+0 records out
34 bytes copied, 0,00725953 s, 4,7 kB/s
$ file -i test.txt
test.txt: text/plain; charset=unknown-8bitUnfortunately, it seems that no standard charset was used, so I had to build a lookup table to decode the custom charset to utf-8. This was a bit tedious, but not hard. It was just a matter of comparing the encoded text with the one readable in the web version of the dictionary.
Decoding the rest of the format, such as control characters with special meanings (quotation, example, pronunciation, etc.), was done in the same way.
When I had what I needed to get the definitions for any desired terms, I wrapped everything in a python module and moved forward to build the bot.
hVortaroBot
To build the bot I used the python-telegram-bot python library.
Apart from giving the definition for the prompted term, the bot supports the following commands:
/casuale— Get the definition of a random term/impiccato— Play the hangman/quiz— Play a trivia quiz/annulla— Cancel the running operation/aiuto— Get usage information
Check it out here: @hVortaroBot
You can see the bot in action in this video:
